Extracting text from the image and translation using Tesseract and Yandex API
Text extraction from the image and translation
In this blog, we will learn about the process of extracting the text from the image by using the open-source Google's Optical Character Recognition OCR engine Tesseract.
Then we will use the multiple language detector and translator Yandex API to detect and translate the language of the text and the image.
What is OCR ?
OCR refers to Optical Character Recognition. As a human we can able to recognize the text from the image but what about the computer and how it can read or parse the data from the image.
 |
At that time we found the OCR and inside the OCR engine, there will be computer vision for the image processing and machine learning technique to train the machine with training data set using certain algorithms to improve the accuracy.
What are the benefits of learning and using OCR?
The ultimate benefit of the OCR is to convert the hard copy into the digital format. Still in this digital world, we are using notebooks and paperback for entering the data. Data entry jobs can be done rapidly with reliability and with more accuracy.
What we'll use in this simple OCR and translation project?
Before moving to the coding part, we need a few prerequisites to work on it
- Python
- Have a quick tour in this python-tutorial and you will get to know about the installation process and basics of python
- Download pycharm IDE community version for better coding
- Pip installation
- Pip wheel contains lots of packages and it'll be very useful
- Install pip using this installation procedure
- Reference - pip installation and setting environment variable
- Setting virtual environment in Python
- We are also going to use Pipenv since it also handles the virtual-environment setup and requirements management.
- Reference - Setting python virtual environment
- Python Imaging Library
- Pillow library is a fork of the Python Imaging Library (PIL) to handle the opening and manipulation of images in many formats in Python.
- Reference - pillow installation using pip
- Python flask
- The Flask web framework to create our simple OCR server where we can take pictures via the webcam or upload photos for character recognition purposes.
- Go through the basic Flask tutorial
- Tesseract OCR
- Python-Tesseract, or simply PyTesseract, the library which is a wrapper for Google's Tesseract-OCR Engine and it is completely open-source and being developed and maintained by the giant that is Google. Follow these instructions to install Tesseract on your machine, since PyTesseract depends on it.
Let's construct our OCR
Now I am creating a simple OCR python program ocr.py to extract the text from the image file. image_to_string in the tesseract OCR helps to extract the text from the image.
pytesseract.image_to_string(Image.open(filename), lang='eng+tam')In this example, OCR can capable of extracting the English as well as the Tamil language in the image. We can change the modify the language in the lang keyword
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
def ocr_core(filename):
# Path of the tesseract engine
pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files (x86)\\Tesseract-OCR\\tesseract.exe'
# Pillow's Image class to open the image and pytesseract to detect the string in the image
text = pytesseract.image_to_string(Image.open(filename), lang='eng+tam')
return text
# Path of the image file
print(ocr_core(r"E:\Coding\Python\OCR\Images\sample_image.PNG"))
Image file to extract the text

Yandex API for language detection and translation
Have a glance at the Yandex documentation to know about the working technique of the Yandex. We need an API key to call the Yandex and sign up for the website to get the API key.
Flask web interface
Learn the basic flask tutorial because our project is mainly integrated with it.
Complete OCR model with language detection and translation
Create a python program main.py under the folder name OCR. This program is doing a few important tasks as listed below
- It is the main function where it callbacks the other vital functions
- OCR function to extract the text
- Language detection function to detect the language
- Language translation function to translate the text and text from the OCR image
- Checks the allowed image file extensions while uploading the file
- Links with Python flask web framework
Comments in each line explain the purpose and the use of the code.
# Import 'flask' for web development
from flask import Flask, render_template, request
# importing 'ocr_core' function from the 'OCR' python file
from ocr import ocr_core
# importing 'language_detector' function from the 'api_detect' python file
from api_detect import language_detector
# importing 'translate' function from the 'api_translate' python file
from api_translate import translate
# define a folder to store and later serve the images
UPLOAD_FOLDER = "E:\\Coding\\Python\\OCR\\ocr_image_process"
# allow files of a specific type
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg'])
app = Flask(__name__)
# app.debug = True
# function to check the file extension
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
# route and function to handle the upload page
@app.route('/', methods=['GET', 'POST'])
def upload_page():
index = 0
if request.method == 'POST':
# check if there is a file in the request
if ('file' in request.files) or ('file1' in request.files):
# This condition will execute when user tries to extracts the text along with translation
if request.files['file'].filename == "":
index = 1
file = request.files['file1']
else:
file = request.files['file']
# Check language choose by the user to translate
if request.form['languages']:
translate_language = request.form['languages']
if file and allowed_file(file.filename):
# call the OCR function on it
extracted_text = ocr_core(file)
# Condition to both text extraction and translation
if index == 1:
detected_language = language_detector(extracted_text)
translated_text = translate(extracted_text, detected_language, translate_language)
return render_template('upload.html',
extracted_text=extracted_text,
detected_language= detected_language,
translated_text=translated_text)
# Extracts the text from the image
else:
return render_template('upload.html',
extracted_text=extracted_text)
# Condition for only translation from the text
if 'translate' in request.form:
# Check language choose by the user to translate
if request.form['languages']:
translate_language = request.form['languages']
text = request.form['translate']
# Calling 'language_detector' function to detect the language
detected_language = language_detector(text)
# Condition when the API fails to detect the language
if detected_language == "":
detected_language = "English"
# Calling 'translate' function to translate the text
translated_text = translate(text, detected_language, translate_language)
return render_template('upload.html', translated_text=translated_text,detected_language=detected_language)
# 'GET' request
elif request.method == 'GET':
return render_template('upload.html')
if __name__ == '__main__':
app.run(debug=True)
Create api_translate.py python program to translate the image. In this script, we need to use the Yandex API key to call the Yandex as mentioned earlier. Use your Yandex API key in the api_key variable.
import requests
import json
def translate(parsed_text, detected_language, translate_language):
# List of language code available to translate the text data
language_dict = {'Tamil': 'ta', 'Hindi': 'hi', 'Telugu': 'te', 'Kannada': 'kn', 'English': 'en'}
# Condition when both 'translate_language' and 'detected_language' are available
if (translate_language in language_dict.keys()) and (detected_language in language_dict.keys()):
translate_language_code = language_dict[translate_language]
detected_language_code = language_dict[detected_language]
# condition when our function can't dect the 'detected_language'
elif (detected_language == "Can't detect the language") and (translate_language in language_dict.keys()):
translate_language_code = language_dict[translate_language]
detected_language_code = "en"
else:
# Default languages
detected_language_code = "en"
translate_language_code = "ta"
api_key = "Use your Yandex API key"
url = api_key+"&text="+parsed_text+"&lang="+detected_language_code+"-"+translate_language_code+"&[format=plain]"
# API call through python
response = requests.get(url)
# Converting to JSON format
result = json.loads(response.text)
# Condition to check the translated text
if 'text' in result.keys():
return result['text'][0]
else:
# When function fails to execute
return "Can't translate"
Create an api_detect.py python program to translate the image. In this script, we need to use the Yandex API key to call the Yandex as mentioned earlier. Use your Yandex API key in the api_key variable.
import requests
import json
# Text received from Flask
def language_detector(text_data):
api_key = "Use your Yandex API key"
url = api_key + "&text=" + text_data
# Python API call to Flask
response = requests.get(url)
# Converting data to JSON format
result = json.loads(response.text)
# MAtching language code with the user's language input
language_dict = {'ta': 'Tamil', 'hi': 'Hindi', 'te': 'Telugu', 'kn': 'Kannada', 'en': 'English'}
# Checking whether language is available
if ('lang' in result.keys()) and (result['lang'] != ""):
lang = result['lang']
return language_dict[lang]
else:
return "Can't detect the language"
Create an ocr.py python program to extract text from the image using Google's Tesseract Optical Character Engine.
try:
# Importing Pillow for image processing
from PIL import Image
except ImportError:
import Image
# Importing Tesseract for OCR engine
import pytesseract
def ocr_core(filename):
# Path of the tesseract engine
pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files (x86)\\Tesseract-OCR\\tesseract.exe'
# Pillow's Image class to open the image and pytesseract to detect the string in the image
# Extracts when both English and Tamil language present in the image
text = pytesseract.image_to_string(Image.open(filename), lang='eng+tam')
return text
Now we are going to create an upload.html Html file in the template folder under the OCR folder. Used to upload the image from the browser and to enter the text data in the text box and to select the language to translate. Save the file in the template folder.
Saving the Js and Jquery files folder under the OCR folder. These help to do click function in the web application.
Html, JS and Jquery files should be in the below directory path.


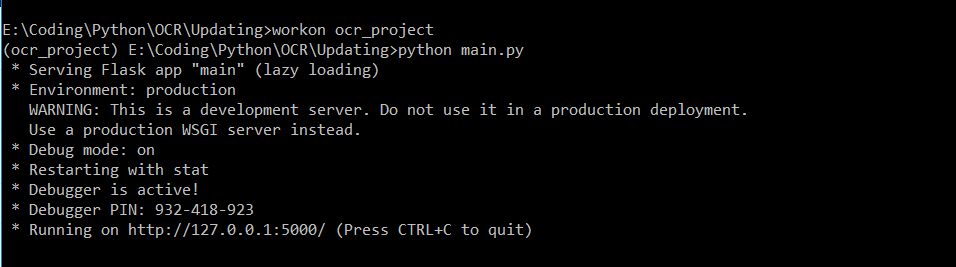
Open the link http://127.0.0.1:5000/ in the browser and you will get the below web page

Click the first radio button to extract the text from the image. Here our Js file works while clicking on the radio button. In this project, we used only the English and the Tamil language. We can add languages separately from the Tesseract.

I used the sample image that I used previously. Here's our web page result after processing OCR.

Sample Tamil language image file to extract the text data

OCR result that we got for this image

Now in the next radio button option, we can translate the text data to any language. Currently, I used only five languages if you want you can add more languages in the api_detect.py and api_translate.py python program. In addition to that, it can predict the language from which text language we try to translate

In this example, I selected the Hindi language to translate my text and here's the output

In the third option, we can do both operations simultaneously. It can extract the text data from the image and it translates the text according to the user's wish

Here the translated output contains a lot of error and this result we got from the Yandex API. We can improve accuracy by using any other translation API's

Code in GitHub
If you are too lazy like me to read all the code and procedure. Then here is the code for you.
Finally, you learned about
- Implementing Computer Vision (CV) in this image processing can increase the accuracy while extracting the text from the image
- Other than the image format, PDF's and multiple format data can be extracted by using Textract package
- Language detection and translation can be improved by training more data set by using the Machine Learning (ML) algorithms
Reference
- https://pypi.org/project/tesserocr/
- https://stackabuse.com/pytesseract-simple-python-optical-character-recognition/
P.S - Most of the people in this generation are workaholic and they are not spending their quality time with their parents, spouse, children who they are thinking them as their world. You can earn money but not love. So spend your time with them.

Good info bro...👍
ReplyDeleteThanks dude
DeleteGood one da
ReplyDeleteI got these KT from you :)
DeleteSuper bro
ReplyDeleteGood one buddy... 😍
ReplyDelete